En el post de hoy compartimos las interesantes conclusiones que SonarSource hizo públicas tras el lanzamiento de su última LTS. Aprendizajes, decisiones, miedos, aciertos y derrotas tras muchos meses de trabajo en seguridad de aplicaciones mediante inspección continua y análisis estático de código.
El artículo original está disponible en el blog de SonarSource. A continuación, presentamos una adaptación y traducción del mismo para la comunidad hispano-hablante.
En 2018, en SonarSource decidimos profundizar en el mercado SAST (Static Application Security Testing). Además de las reglas existentes para detectar vulnerabilidades, se desarrolló un nuevo motor de análisis de seguridad para detectar vulnerabilidades de tipo inyección complejas, enfocándose en la fase inicial en Java, C# y PHP.
Como éramos nuevos en el campo de la seguridad, buscamos casos de prueba para ayudarnos a entender mejor qué tipos de problemas deberíamos ser capaces de detectar. Rápidamente encontramos el famoso OWASP Benchmark, que se compone de 2.740 casos de prueba de Java. Este benchmark nos ayudó mucho a arrancar nuestro desarrollo y medir nuestro progreso durante la fase inicial.
En este post, voy a explicar cómo usamos el OWASP Benchmark para mejorar nuestro taint analysis (en un contexto SAST, los datos que vienen de los usuarios se consideran “tainted”) y lo más importante, por qué decidimos que conseguir una puntuación perfecta (de 100) en el OWASP Benchmark no era el objetivo que perseguiamos.
Los primeros 10 meses
Comenzamos la implementación de nuestro analizador “taint” apuntando a inyecciones SQL, probablemente el tipo de vulnerabilidad más famosa. Identificamos las fuentes básicas de entrada de usuario (ej: HttpServletRequest.getParameter(“ParamKey”)) y las APIs donde la vulnerabilidad puede ser explotada (los “sumideros” en la jerga SAST). Estábamos bastante orgullosos de nuestros resultados iniciales, pero queríamos confirmarlos en proyectos más concretos, por lo que empezamos a usar el OWASP Benchmark.
Los casos de prueba del benchmark se dividen en dos conjuntos principales: vulnerabilidades de inyección y vulnerabilidades de no inyección (ver Apéndice II para más detalles). Debido a que estábamos desarrollando un analizador “taint” (es decir de inyección por parte de usuarios), nos centramos sólo en los 1572 casos de prueba de vulnerabilidades de inyección.
Nuestros primeros análisis de estos casos fueron prometedores, con un 27% de positivos. Pero también había un 21% de falsos positivos, así que sabíamos que teníamos más trabajo que hacer.
Analizar en detalle los falsos positivos nos hizo darnos cuenta de que necesitábamos rastrear los valores en arrays y colecciones. También tuvimos que añadir soporte para objetos y para accesos de campo a nuestra variable string. Finalmente, necesitábamos añadir fuentes adicionales, “sumideros” y los métodos estándar que se utilizan para hacer seguro el flujo de datos (es decir, “sanitizers”).
A lo largo del camino hemos estado lanzando nuevas versiones a nuestra comunidad, y fue muy emocionante ver que el feedback llegaba y los resultados mejoraban después de cada lanzamiento. Finalmente, alcanzamos un 74% de positivos con un rendimiento bastante bueno (ver Apéndice III), pero no estábamos satisfechos con el 30% de falsos positivos (los falsos positivos son lo peor, pueden matar la confianza en un producto). Profundizando en esto, empezamos a entender algunos de los límites del OWASP Benchmark.
Alcanzando los límites
Casos de prueba extraños
Sensibilidad en la ruta de ejecución
Mientras indagábamos en los problemas generados por nuestro analizador, descubrimos que muchos de los casos de prueba del OWASP Benchmark estaban relacionados con la sensibilidad en la ruta de ejecución, es decir, en la capacidad de detectar que una ruta de ejecución no será alcanzable bajo ciertas condiciones. Todos los casos de prueba de sensibilidad en la ruta de ejecución contienen una declaración if que siempre es verdadera o falsa, y la vulnerabilidad está en algún lugar del código que no es realmente alcanzable. Véase BenchmarkTest00104 para un ejemplo concreto.
En SonarSource, creemos que en la vida real, si existe una vulnerabilidad en una rama del código, eventualmente será llamada. Además, si realmente tienes código muerto y condiciones que siempre son verdaderas/falsas, eso no es un problema de seguridad, es un error y tenemos otras reglas (RSPEC-2589, RSPEC-2583, RSPEC-1850, RSPEC-1145) para eso.
Así que decidimos descartar los casos de prueba de sensibilidad en la ruta de ejecución y no considerarlos en absoluto, independientemente de la debilidad que se suponía que debían demostrar. Para ser claros, nuestro analizador “taint” no es sensible a la ruta de ejecución y probablemente nunca lo será. Si hay una vulnerabilidad en el código inalcanzable, vamos a detectar un bug porque creemos que debe ser arreglado.
Trust Boundary
Hay 126 casos de prueba en el benchmark relacionados con algo llamado “Trust Boundary”. Resulta que no son realmente explotables y Dave Wichers, el autor principal del “Benchmark” de OWASP propuso eliminarlos en una futura versión del benchmark. Creemos que sería incorrecto plantear cuestiones sobre estos casos. Así que también quitamos esos casos del alcance de nuestro analizador.
Path traversal
Por último, el 78% de los casos de prueba de Path Traversal consideran que la instanciación de un archivo java.io.File es un problema. Nosotros no creemos que eso sea correcto (lo mismo se aplica a java.io.FileOutputStream o java.io.FileInputStream a partir de datos proporcionados por el usuario o comprobando si un archivo existe con File.exists()). El problema no es instanciar la clase, sino realizar acciones sobre estos objetos (lectura/escritura) que están en riesgo. Por lo tanto, también excluimos esos casos de prueba.
¿A dónde nos llevó eso?
En total, de los 1572 casos de prueba de vulnerabilidades de inyección del OWASP Benchmark, hemos descartado 372 y mantenido los 1200 que consideramos relevantes para pruebas de seguridad.
Considerando solo esos 1200 casos de prueba, la edición SonarQube Developer (las versiones a partir de septiembre de 2019) obtiene una puntuación OWASP de 84 con una tasa de positivos del 85% y una tasa de falsos positivos del 1%. Insistimos, esto se logró centrándose en aportar valor y haciendo lo que tiene sentido, más que en perseguir la puntuación OWASP en sí.
¿Qué viene ahora?
Continuaremos mejorando nuestro motor SAST para reducir nuestra tasa de falsos positivos con el tiempo, y obviamente trabajaremos para mejorar nuestra tasa de positivos. Pero hoy más que nunca, conseguir una increíble puntuación en OWASP Benchmark no es nuestro objetivo. Sería completamente erróneo obtener una puntuación de 100 ahora que entendemos los límites del benchmark.
El OWASP Benchmark proporcionó un gran conjunto de casos de prueba con los que arrancar nuestro motor SAST, pero no es el final del viaje. ¡Todavía hay mucho más por hacer! Por ejemplo, queremos mejorar nuestra cobertura del resto de las categorías del OWASP Top 10 2017, como A4-XXE y A8-Insecure Deserialization. Para todas las categorías de OWASP necesitamos seguir la tendencia de los frameworks de Java (Vert.x, SparkJava) y considerar las especificaciones de los establecidos (Spring Dependency Injection). También necesitamos mejorar nuestra regla XSS para considerar las tecnologías front-end, ya que actualmente dejamos de mirar el flujo de ejecución cuando los datos salen del ámbito de Java. Necesitamos continuar el seguimiento de los datos en el sistema de plantillas (Thymeleaf, JSP) o en el front-end de JavaScript (React, Angular, Vue.js).
Obviamente, continuar usando el OWASP Benchmark para este trabajo sería ideal, pero esas cosas no están incluidas en el benchmark hoy en día y no es seguro que se añadan nuevos casos de prueba en el futuro. El proyecto está buscando colaboradores, y aunque SonarSource podría contribuir - es parte de nuestro ADN contribuir al código abierto - eso se vería raro, y es posible que sin quererlo podamos sesgar los resultados.
Además, obtener buenos resultados en cualquier benchmark no significa necesariamente que puedas detectar vulnerabilidades del mundo real. Como consecuencia, necesitamos otras fuentes de casos de prueba (bases de datos CVE, GitHub commits) para estar seguros de que nuestro analizador puede detectar vulnerabilidades en la mayoría de las categorías del OWASP Top 10 2017. Para asegurarnos de que podemos encontrar estas vulnerabilidades necesitamos buenos ejemplos a partir de los cuales trabajar, así que estamos confiando en los comentarios del commit de correcciones de vulnerabilidades en proyectos de código abierto, y luego usando el código de “antes” como ejemplo. Estudiar estos commits nos ayuda a entender mejor qué tipos de vulnerabilidades se arreglan hoy en día y cómo los desarrolladores se las arreglan para mitigarlas.
Los resultados de este esfuerzo ya están disponibles para pipelines en ediciones SonarQube Developer y también en SonarCloud (que es totalmente gratuito si tu proyecto es de código abierto). Actualmente soportamos inyecciones para Java, C# y PHP, y ya estamos trabajando en el soporte para Python.
Apéndice I: OWASP Benchmark Score
Aquí están las bases del cálculo del OWASP Benchmark Report:

Para obtener una puntuación de 100, tienes que encontrar todos los problemas sin marcar ningún falso positivo.
Si miras la puntuación oficial publicada por OWASP para el “Plugin de Java de SonarQube”, verás que está lejos de ser buena, pues muestra un 33%. Esta mala puntuación está relacionada con el hecho de que el OWASP Benchmark fue medido por última vez con el SonarJava 3.14, que fue publicado en septiembre de 2016 - hace casi tres años, en el momento de escribir este artículo - y en ese momento nadie en SonarSource buscaba mejorar esta puntuación porque el desarrollo de reglas de seguridad no era nuestra principal preocupación.
Las cosas han cambiado mucho desde esa versión. Si consideras sólo los 1200 casos de pruebas de vulnerabilidad de inyección, la edición para desarrolladores de SonarQube obtiene una puntuación OWASP de 84 con un índice de positivo de 85% y un índice de falso positivo de 1%.
Esta puntuación se alcanzó usando SonarQube Developer Edition 7.9.1 corriendo el Motor de Seguridad 8.0-M1.
Nota: Tratamos de producir la información necesaria para la puntuación de OWASP Benchmark, pero por razones técnicas y porque descartamos 372 casos de prueba, nos resultó más fácil calcular nuestra propia puntuación OWASP.
Apéndice II: Contenido de OWASP Benchmark
Contenido oficial
El OWASP Benchmark sólo apunta a Java. Está compuesto por 2740 casos de prueba almacenados en un único directorio llamado “testcode”. Los resultados esperados se describen en un archivo CSV. Para cada caso de prueba se detalla:
-
a qué tipo de vulnerabilidad apunta
-
si se espera un problema
-
el identificador CWE relacionado con el caso de prueba
El benchmark cubre 11 tipos de vulnerabilidad que agrupamos en 2 conjuntos:
Vulnerabilidades de inyección:
-
Inyección SQL: 504 casos de prueba
-
Path Traversal: 268 casos de prueba
-
Inyección de LDAP: 59 casos de prueba
-
Inyección de comando: 251 casos de prueba
-
Inyección de XPath: 35 casos de prueba
-
Cross-Site Script: 455 casos de prueba
Vulnerabilidad de no inyección:
-
Criptografía: 246 casos de prueba
-
Hashing: 236 casos de prueba
-
Cookies seguras: 67 casos de prueba
-
Trust Boundary: 126 casos de prueba
-
Weak Random Number: 493 casos de prueba
Contenido de SonarSource
Con el objetivo de aclarar qué casos de prueba excluímos, clonamos el OWASP Benchmark y reorganizamos los casos de prueba por tipo de vulnerabilidad (sqli, pathtraver, ldapi, …) y subdirectorios issue-expected / no issue-expected. Esto nos ayudó a ver fácilmente en SonarQube/SonarCloud cuando se detectaban problemas inesperados.
Apéndice III: Rendimiento
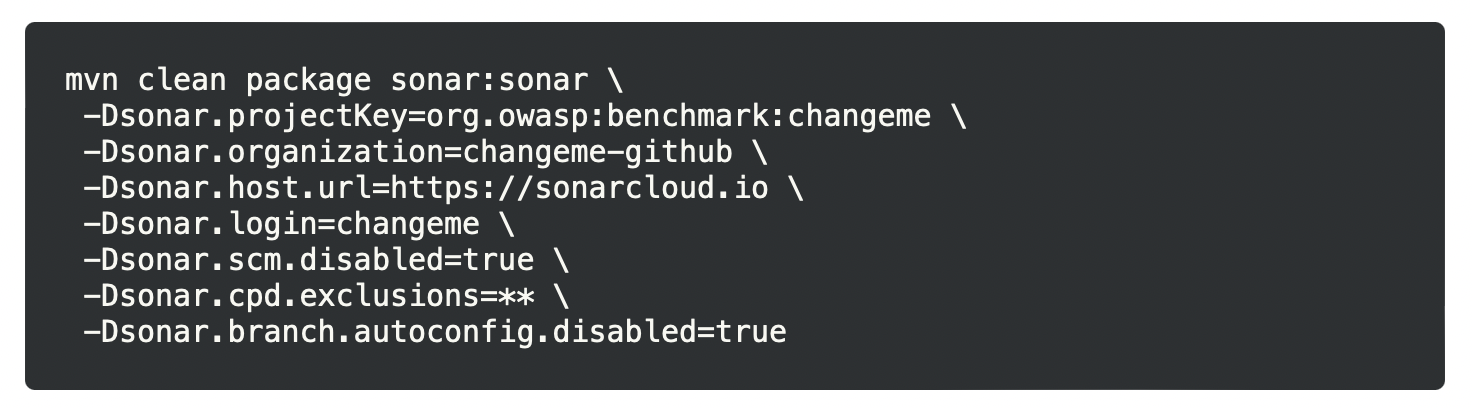
Si quieres reproducir las puntuaciones que mencionamos en este documento, puedes clonar nuestra propia versión de OWASP Benchmark (o la oficial) y ejecutar tu propio escaneo en SonarCloud.io. Aquí hay un ejemplo de línea de comandos para activar tal escaneo:
A pesar de que descartamos algunos casos, analizamos todos los archivos disponibles en el OWASP Benchmark, sólo están en directorios especiales para no ser contados cuando calculamos la puntuación.
En una máquina promedio hecha de un Intel Core i5 3570 a 3.40 GHz + 16Go de RAM, el análisis del OWASP Benchmark debería tomar menos de 3 minutos.