
Al escribir una regla para el análisis estático del código puede ser que no dé los resultados esperados. Por desgracia, nombrar un falso positivo a menudo es mucho más fácil que arreglarlo. Por ello, en esta publicación, discutiremos cómo los diferentes tipos de reglas dan lugar a diferentes tipos de falsos positivos, cuáles son más fáciles de corregir y cómo te pueden ayudar. Acabaremos con información sobre cómo los problemas que son falsos positivos, pueden seguir siendo indicadores verdaderos de que el código puede cambiar.
Primero echemos un vistazo a lo que significa “falso positivo”. Hay dos cuestiones que dan forma a la definición. Primero, ¿hay un problema real en el código? En segundo lugar, ¿se detecta un problema en el código? Combinarlos nos da una matriz cartesiana de 2x2:
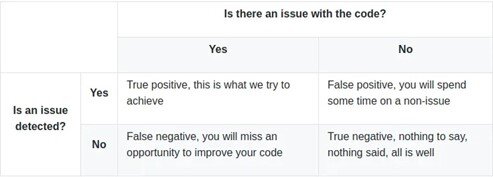
¿Por qué hay falsos positivos?
Hay varios tipos de reglas que se basan en diferentes técnicas de análisis. Por lo tanto, no es de extrañar que existan diferentes razones para los falsos positivos.
Una distinción importante es si la regla necesita calcular las propiedades semánticas de su programa. Por ejemplo, ¿Puede esta “cadena” estar vacía? ¿Es posible que ocurra una llamada a la función “b” antes que una llamada a la función “a”? O si solo necesita depender de propiedades sintácticas… ¿El programa usa “goto”? ¿Este “switch” maneja todos los valores posibles de una “enum”? Veamos el impacto que tiene esta diferencia.
Teorema de Rice
El teorema de Rice afirma que cualquier propiedad semántica no trivial de un programa es indecidible. Un caso especial muy conocido de este teorema es el problema del halting, cuya imposible solución fue probada por Alan Turing. No hay forma de escribir una regla que pueda detectar, dado el código fuente de otro programa, si este otro programa se detendrá o se ejecutará indefinidamente.
Afortunadamente, estos teoremas no significan que el análisis estático esté condenado al fracaso. Hay heurísticas que funcionan razonablemente bien en muchos casos útiles. Simplemente no es posible escribir algo que funcione en todos los casos. Las reglas que se basen en propiedades semánticas siempre estarán sujetas a falsos positivos.
Reglas no semánticas
No todas las reglas se basan en propiedades semánticas, ya que algunas son mucho mas simples, pero aún pueden generar falsos positivos. Eso puede deberse a que la implementación tenga errores, o a que la especificación exacta sea difícil de conseguir.
Veamos un ejemplo de una regla simple: no se deben usar valores octales. Los literales octales comienzan con un “0” en C y C++. No se utilizan con mucha frecuencia y existe el riesgo de que alguien que lea el código los confunda con un literal decimal.
Por ello, se creó una regla para detectar esta situación. Se excluyen correctamente algunos casos especiales desde el principio (por ejemplo, el literal “0” es un literal octal, pero es la única forma sensata de escribir 0, y en este caso, el valor octal y el decimal son iguales). Hasta ahora, todo bien, la regla se agregó al analizador.
Por desgracia, esta regla tenía lo que consideramos un falso positivo en su especificación. En los sistemas de archivos POSIX, los permisos se establecen para usuario/grupo/otros, y estos permisos realmente tienen sentido ya que son un caso en el que usar la notación octal, porque cada dígito coincide exactamente con un alcance de permiso (el permiso “0740” significa “7” para el usuario, “4” para el grupo y “0” para los demás). Por lo tanto, decidimos que, en este contexto específico, un literal octal no debería plantear ningún problema.
int const secretCode1 = 1234; int const secretCode2 = 0420; // In fact, this number is 272 in decimal
Por ello, se creó una regla para detectar esta situación. Se excluyen correctamente algunos casos especiales desde el principio (por ejemplo, el literal “0” es un literal octal, pero es la única forma sensata de escribir 0, y en este caso, el valor octal y el decimal son iguales). Hasta ahora, todo bien, la regla se agregó al analizador.
Por desgracia, esta regla tenía lo que consideramos un falso positivo en su especificación. En los sistemas de archivos POSIX, los permisos se establecen para usuario/grupo/otros, y estos permisos realmente tienen sentido ya que son un caso en el que usar la notación octal, porque cada dígito coincide exactamente con un alcance de permiso (el permiso “0740” significa “7” para el usuario, “4” para el grupo y “0” para los demás). Por lo tanto, decidimos que, en este contexto específico, un literal octal no debería plantear ningún problema.
Un desarrollador astuto puede preguntarse: ¿qué pasa si utilizo un literal octal para establecer indirectamente un permiso?
void f (bool b) {
int mask = 0770;
if (b) {
mask |= 0007;
}
open(“some_path”, O_WRONLY , mask) ;
}
En esta situación, ¿deberíamos permitir los 2 literales octales o no? No hay una respuesta perfecta:
• Podemos pecar de evitar falsos positivos al decidir que todos lo valores octales con 3 dígitos son aceptables. Al hacerlo, introducimos falsos negativos, que suele ser el caso cuando intentamos evitar falsos positivos.
• Podemos rastrear si el valor se usa o no para un permiso POSIX. Esto hace que la regla sea más compleja (y por lo tanto más lenta), y también hace que esta regla sea un tema del teorema de Rice, cuando no lo era antes.
• Podemos decidir informar de esos casos, asumiendo (comprobado al observar una gran cantidad de código fuente abierto) que este no es un patrón común.
En este caso, se decidió que una tasa baja de falsos positivos era más aceptable que las otras opciones y se escogió la tercera opción. Desafortunadamente, aquí no acaba la historia. Varios meses después, se descubrió que si se llama a una función POSIX con varios parámetros octales, un bug en la implementación provocaba que surgiera un “issue”. Que ya lo corregimos.
Pequeña taxonomía
Hemos visto tres tipos de falsos positivos. Si bien puede haber una categorización más precisa, estos tres tipos son lo suficiente diferentes como para requerir acciones diferentes:
Falsos positivos semánticos: estos son los falsos positivos relacionados con el teorema de Rice. Ocurren cuando necesitamos conocer algunas propiedades semánticas de un programa. Por ejemplo, si una variable puede ser nula en un punto determinado del código, o si un índice está dentro de los límites de una matriz
Especificación de falsos positivos: ocurren con mayor frecuencia para las reglas de Code Smell. Un Code Smell es simplemente un indicador, no un bug claro, por lo que no hay criterios definidos. Eso significa que decidir si el código huele bien o mal queda sujeto a la interpretación. Siempre hay un área gris entre lo bueno y lo malo, y se necesita algo de tiempo y muchos ejemplos de código para obtener buenas reglas que funcionen en la mayoría de los casos comunes.
Errores que causan falsos positivos: a veces, solo tenemos un error en nuestra implementación. No detectamos lo que se supone que debemos detectar.
¿Por qué debemos evitar falsos positivos?
Hemos visto que evitar falsos positivos no es un absoluto. Por lo general, se presenta como un compromiso, las compensaciones siendo una implementación más compleja (más lenta y más propensa a errores) y la aparición de falsos negativos. Llevado al extremo, podemos crear un producto con una tasa de falsos positivos de 0. Simplemente sin informar nunca de nada. Pero un producto así no sería muy útil, ¿verdad?
Por otro lado, podría haber buenas razones para seleccionar una posición en el lado opuesto del espectro: informar de todo. Por ejemplo, si nos estuviéramos enfocando en un software crítico para la seguridad, donde un bug puede tener consecuencias nefastas, probablemente favoreceríamos una estrategia donde minimicemos los falsos negativos, con el coste de que requiera más tiempo para los desarrolladores, que tendrán que filtrar manualmente los falsos positivos producidos por un análisis.
Como ejemplo, en el analizador para C y C++, se incluyó un conjunto de reglas que no fueron diseñadas por SonarSource, pero que provienen de las pautas de MISRA para un software crítico para la seguridad. Estas reglas se diseñaron con una mentalidad en la que los falsos positivos no son tan importantes si pueden ayudar a evitar los malos comportamientos, incluso cuando la amenaza es poco común. Y los implementamos tal cual.
En SonarSource, sin embargo, creen que mientras sea posible, deben favorecer la minimización de los falsos positivos tanto como sea posible. ¿Por qué? Según su experiencia, una herramienta que informa demasiado, es una herramienta a la que se dejará de prestar atención después de un tiempo.
Además, quieren permitir que el análisis estático sea parte del flujo de trabajo de desarrollo, con la posibilidad de que un equipo decida bloquear una request si no pasa los criterios mínimos de calidad. Hacerlo sería doloroso si se arrojaran muchos falsos positivos.
Volviendo a cómo manejan las reglas MISRA, hay casos en los que implementaron dos versiones, una de las cuales es una implementación estricta de la regla MISRA, y otra que está más cerca de su filosofía preferida: reportará menos problemas, reteniendo solo los más importantes. Para estas reglas inspiradas en MISRA, creen que pueden reducir razonablemente el ruido sin perder demasiado valor. Puedes seleccionar la versión que prefieras según tu contexto.
¿Por qué debemos evitar falsos positivos?
En las IU de SonarQube y SonarCloud, puedes marcarlas como tales, para que ya no te molesten más con este problema. Pero esta es solo una solución a corto plazo. Probablemente haya mejores opciones que tomar.
Repórtalos
Como comentamos anteriormente, están ansiosos por disminuir la tasa de falsos positivos en sus productos. Entonces, si ves uno, infórmalo en el foro de su Comunidad. Si tienes alguna idea de por qué el código genera un falso positivo, ¡mejor! Podrán corregirlo más rápido. Actualmente están añadiendo algunas características a sus productos para permitirte informar de falsos positivos de manera fácil y efectiva.
En algunos casos, especialmente con falsos positivos semánticos, les resultará difícil eliminar un falso positivo. Los teoremas son como los jefes finales en un videojuego, son muy difíciles de derrotar. Pero se hace el mayor esfuerzo de todas formas. Para especificar falsos positivos, tendrán que ver si están de acuerdo con tu evaluación de la situación y luego los corregirán. Y, por último, los bugs que causan falsos positivos tienen una alta prioridad en sus trabajos pendientes, y, por lo general, se tratan rápidamente.
Post-mortem de un falso positivo
Antes de llegar a la conclusión de este artículo, tomemos un desvío y analicemos un informe de un falso positivo que obtuvieron en el foro de su comunidad. Va sobre la regla de que las expresiones idénticas no deben usarse en ambos lados de un operador binario, cuyo propósito es detectar código defectuoso como `(a == b && a == b)´ , que probablemente sea el resultado de un error de copy/paste. El código de usuario era el siguiente:
If (!DoSomething () ) return xml GoToParentNode () xml GoToParentNode ();
Con el siguiente comentario:
Como probablemente puedes ver, este retorno salta dos veces en la estructura XML, si el primer salto es exitoso. De lo contrario, devolverá ‘falso’ (‘GoToParentNode’ tiene el tipo de retorno ‘bool’). Si bien podría ser discutible si esto es ideal y si no sería más claro escribir esto en varias líneas con supuestos individuales, esto es válido y es la manera más sucinta.
Se está completamente de acuerdo en que es un falso negativo para esta regla (en la categoría de bugs causando falsos positivos), y se creó un ticket con el fin de corregir esto. De todas formas, el segundo párrafo es muy interesante: este código no es el mejor posible. Mientras se puede deducir lo que el código significa, hay que aumentar el nivel de conocimiento para poder leer y comprender este código.
Navegar por el árbol XML de esa manera podría ser un patrón común en este código base, en cuyo caso, está perfectamente bien, porque los mantenedores de este código han sido entrenados para leer dicho código. Pero por lo demás, aunque es correcto y sucinto, este código es demasiado inteligente y es un Code Smell. No el que se indicó, pero sí un problema.
Sería mejor escribir este código de esta manera absurda, que muestra claramente que estamos tratando de navegar hasta el grandparent:
Úsalos como una pista
A pesar de haberse comprometido a reducir la cantidad de falsos positivos en sus analizadores, cuando encuentre uno, aún puede hacer una pausa y reflexionar sobre por qué sucede.
Un analizador estático es una herramienta que intenta comprender el código fuente. Que es lo que hacen los desarrolladores todo el tiempo. Obviamente, los desarrolladores, cuando se lo proponen, son mucho más precisos que cualquier analizador estático. Pero al mismo tiempo, tienden a cansarse después de un tiempo. El código fuente debe ser fácil de entender y razonar.
Si una herramienta no puede hacerlo, ¿estás seguro de que los desarrolladores pueden hacerlo de manera constante, incluso un viernes por la noche después de una buena cena?
Si una herramienta no puede hacerlo, ¿estás seguro de que los desarrolladores pueden hacerlo de manera constante, incluso un viernes por la noche después de una buena cena?
Conclusión
En este documento explicamos qué son los falsos positivos y por qué son un componente inherente del análisis estático que nunca pueden ser realmente eliminados. Y por qué, sin embargo, se trata de reducirlos.
Cuando encuentres uno, puedes marcarlo como tal e informar. Y al mismo tiempo, tómatelo como una pista. Un indicio de que probablemente haya algún problema con el código que provocó el falso positivo (aunque el problema real puede no estar relacionado en absoluto con el problema del que informaron). Una pista de que este código tiene el potencial de mejorarse.
Y hasta aquí este post sobre los falsos positivos traducido de este artículo de Sonar.
Si quieres más información sobre este tema, puedes ponerte en contacto con nosotros a través de este formulario.